The volume of visual data in the world is bigger than ever. In fact, over the next few years up to 2025, global data creation is projected to grow to more than 180 zettabytes. If you are working with computer vision models or AI use cases involving images and videos, you will understand the explosive volume of data and information contained in the datasets.
Current visual data labeling and refinement methods rely on time and labor-intensive processes to create training datasets for computer vision models, which can still present some issues due to human error.
With this ever-growing volume of data, managing, searching, and identifying the most valuable instances will be critical. But, without the proper tools in place, it will be a nearly impossible task.
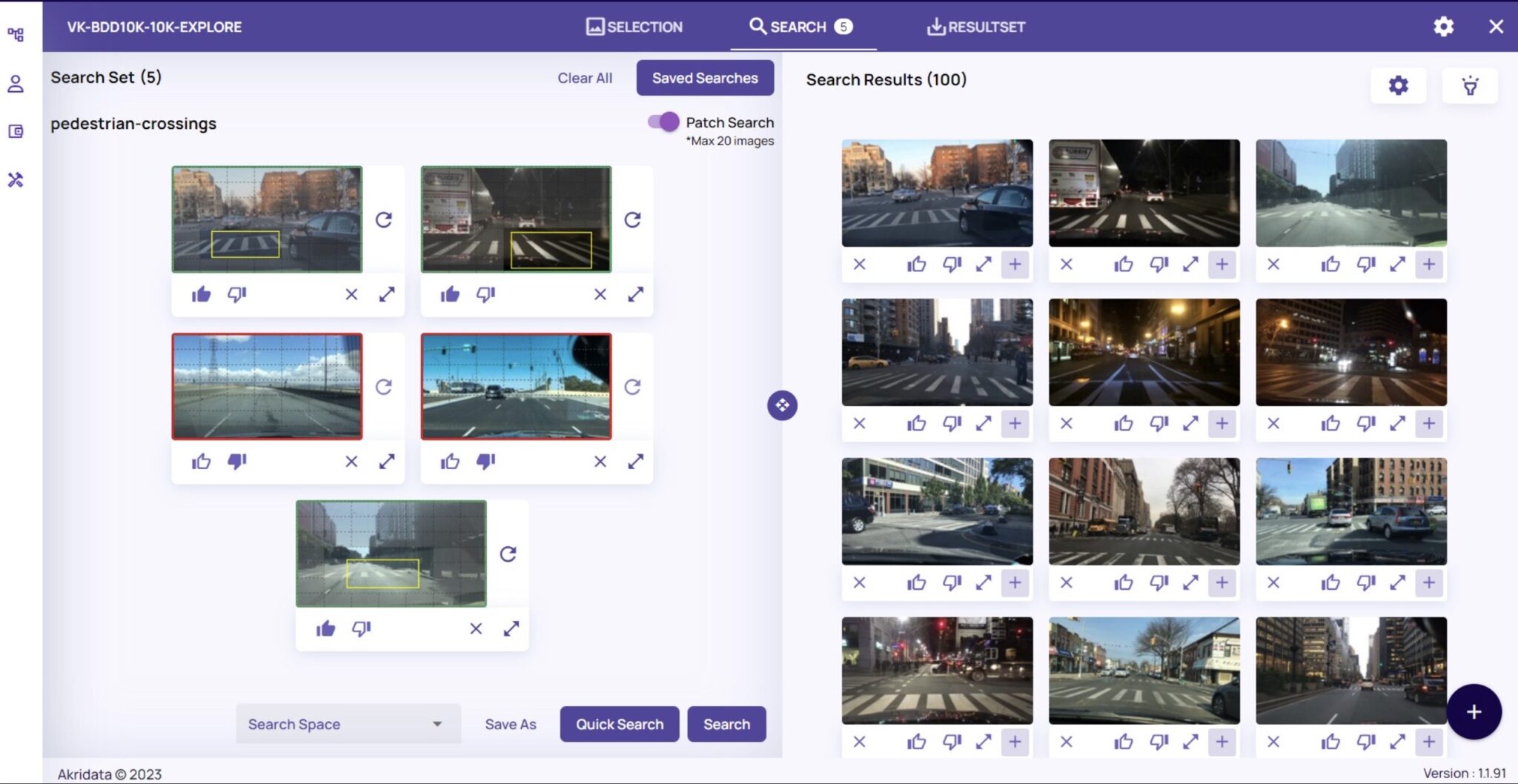
That’s why Akridata built Data Explorer and has created the ground-breaking, industry-first ‘Patch Search’ feature. Data Explorer’s Patch Search allows users to draw a bounding box around a desired region of interest within a frame to identify similar images based on the latent structures and characteristics of the photo, even across multiple datasets.
By defining the Region of Interest within visual datasets, organizations can better train their computer vision models and improve their accuracy, image segmentation, and data tracking and analysis. Using Data Explorer’s Patch Search to define the region of interest reduces the manual hours required to sift through large volumes of datasets to find images that match a specific pattern or an object of interest.
How does Region of Interest help in visual data analysis?
For organizations that rely on visual data, Region of Interest is critical to image classification. Image classification trains an ML algorithm to recognize specific images by defining the important, recognizable objects in an image, like the pedestrians in traffic camera footage. Through Region of Interest, images can then be further segmented, or defined from a background (i.e. a specific genus of tree in a field with multiple trees and plants) by properties like color, sizes, borders, and shapes.
Region of Interest is also highly useful for object detection. Similar to how a human can look at a photograph and pick out specific objects, in computer vision, the goal is to have the ML platform identify and detect objects, as a human would. Object detection is very important for the safety of autonomous cars, security and surveillance purposes, as well as for image retrieval.
To more effectively comb through and analyze large visual datasets for important objects or images, Region of Interest is a useful technique.
The Challenges of Region of Interest Extraction
Let’s say you are in the manufacturing industry and trying to create a model to help with quality control and identify cracks or breaks within concrete slabs. If you are building the model to detect the cracks or breaks, you need to first have a dataset with enough examples of that instance and to have them labeled. Taking a step back, if you’re working with an unlabeled dataset, you have to sift through the massive quantities of images to find enough examples to train your model. And, if you’re working with a large dataset, as most visual datasets are, this is an extremely time-consuming and exhaustive task.
But there is still a chance that the model will identify unintended characteristics and create undesired biases.
Further, you would want to identify as many diverse examples of these breaks as possible, as they will not all be uniform in size, shape, or location in these image frames.
Let’s say you want to identify examples of mobile phones. Your dataset may contain images of people talking on their phones, or their phones sitting on a table, or someone texting, AND you would still need to account for the various types of phones, colors and the variety of cases that go on a phone, and the orientation of the phone itself.
As you can see, there are countless factors that could go into building the most robust training dataset for your model.
However, while Region of Interest offers clear advantages, unless your visual data is already labeled, Region of Interest can balloon into a largely manual and time-consuming process. Additionally, if you’re only looking for a small piece of an image, Region of Interest can also prove to be difficult to find every single instance of, say, a corner or top of an image.
There are other issues as well in Region of Interest extraction. In images with partial object occlusions or cluttered environments, it can prove challenging for ML to successfully and accurately find and then isolate objects.
Noise and distortion are two other common challenges with Region of Interest extraction. Image noise occurs when there are unusual or random variations in the brightness of color in images. Image noise is a frequent result of electronic noise, like a whirring fan or moving car. Image noise can make it difficult for ML to properly identify objects, as the change in brightness may be confusing and cause misidentification. Distortion in visual datasets, caused by improper axis scaling, can also create issues for accurate Region of Interest.
Then, there’s the problem of limited computational resources. Whether it’s crunched time, a lack of team members with the expertise to perform Region of Interest extraction, a shortage of computer memory, or all of the complexities that can arise in manual Region of Interest extraction, this method of analyzing visual data brings about plenty of flaws that can slow down progress and efficiency when working with large visual datasets.
That’s where Akridata comes in.
Solving Region of Interest Challenges with Akridata
Akridata Data Explorer is a custom-developed ML platform built for exploring, analyzing, and curating exascale visual data training sets. Akridata was built by a team of engineers and data scientists sick and tired of the challenges of manually searching, collecting, and curating visual data sets.
Real-World Use Cases that benefits from Image Patch Searches
If you’re curious how Akridata works in the real world, check out this example of our work with autonomous cars for nuScenes. nuScenes is a public large-scale dataset for autonomous driving, and uses Akridata to analyze images and create a 2D point cloud viewed as a cluster map. From there, Data Explorer is used to visualize the dataset, explore and understand, , and perform powerful visual search within a large cluster.
Akridata Data Explorer is also useful in medical imaging as well, and is a powerful tool to more thoroughly and easily search through large sets of visual data, like medical images. Akridata was used for a Kaggle competition for an RSNA Screening Mammography Breast Cancer Detection, to perform coreset selection for the fastest iteration possible.
Akridata’s powerful search function was designed to run image-based similarity searches on millions of images, in seconds, and then refine those results through interactive scoring on a subset of data to search for domain-specific features. With the search function, users instantly gain the ability to quickly identify similar images based on characteristics and then refine that search even further.
Additionally, Akridata’s Patch Search bounding box allows you to isolate regions of interest to show the model what to look for and create a more specific data set. Data Explorer goes beyond a simple-image-based search and uses Patch Search to mark small patches (one patch per image) and conduct a search based on these patches. This improves searching in large images and also enhances accuracy.
If you’re ready to experience a more seamless, efficient workflow when it comes to searching and exploring visual datasets, it’s time to try Akridata Data Explorer.
Learn more and get started with Akridata today: https://www.akridata.ai/



No Responses