Development cycles in modern computer vision rely heavily on large visual datasets – images of various types, videos from different sources or a mix of the two. The raw content is somehow curated to form a training set and a test set that are used to develop, train and test a DL model.
But how does the curation process work? How do you find from the massive raw dataset of images and videos, a high quality, diverse, subset for training and another for testing?
Data scientists know that searching through massive visual and video datasets for the relevant images is typically a painfully long, laborious, and tedious process.
There’s the naive, manual, approach, but that means spending hours upon hours searching through thousands or tens of thousands of images or hours of video – and hopefully finding the images or frames you need.
Then, there is the semi automatic approach, writing endless scripts, using basic features like colors, edges, shapes etc. It might be enough if your data is static and homogenous, but for modern applications, expect a large variation in image sizing, resolution, lighting conditions, scenes, occlusion and so on. That’s hardly static or homogenous.
You could annotate all the raw data you have and apply queries on the metadata. However, labeling and annotating visual data takes a lot of effort, it’s expensive, and is prone to inaccuracies during the annotation process. On top of that, to reuse the data for a new project, will you need to re-annotate it with new objects, tags or masks?
Neither of these methods is particularly efficient or effective, and eventually will be too costly, take too much time or both.
That said, searching through massive datasets for relevant images is a standard practice for data scientists, as clean, high-quality data is a must for model training and development.
So, what’s the solution to more efficient, speedier image searching?
Introducing Data Explorer’s Text–to–Image Search
Data Explorer is a platform that saves time curating and cleaning visual data, to create a base of high-quality data for the development cycle, every step of the way.
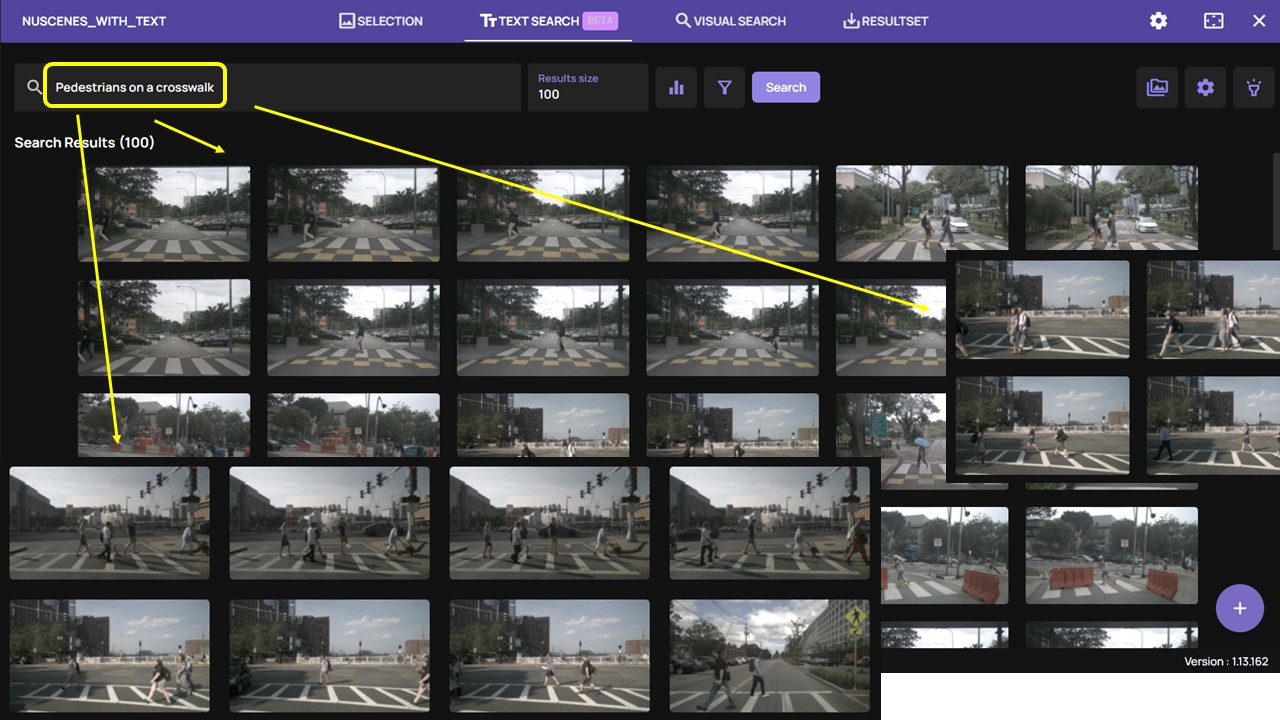
It offers an advanced text–to–image search function that gives users the ability to quickly and easily search through images and videos, without any annotations. This is particularly effective and efficient for working with very large datasets, since the search is completed within seconds, and is based on natural language processing (NLP).
Text–to–image search can also be combined with image-based-search, to find the most relevant subset of images or frames from the raw data within seconds.
How does Text–to–Image Search work?
Data Explorer’s text–to–image search is simple to use. Here’s how it works:
- Open a Data Explorer account and connect it to your data – it will not be moved or copied at any point.
- Simply type whatever you are searching for within the search bar. Text searches can be as simple as a single word.
- The platform will process the text query and provide the relevant images or frames.
- This process can be repeated and refined as many times as you’d like, to find all of your needed images.
Optional: After applying the text based search, you can also run Patch search to further enrich your results.
Get started with Data Explorer
Data Explorer saves you hours by providing a simple interface to run a text–to–image search on raw data, quickly providing the relevant subset of images or video frames.
To learn more, visit us at akridata.ai or click here to register for a free account.

No Responses