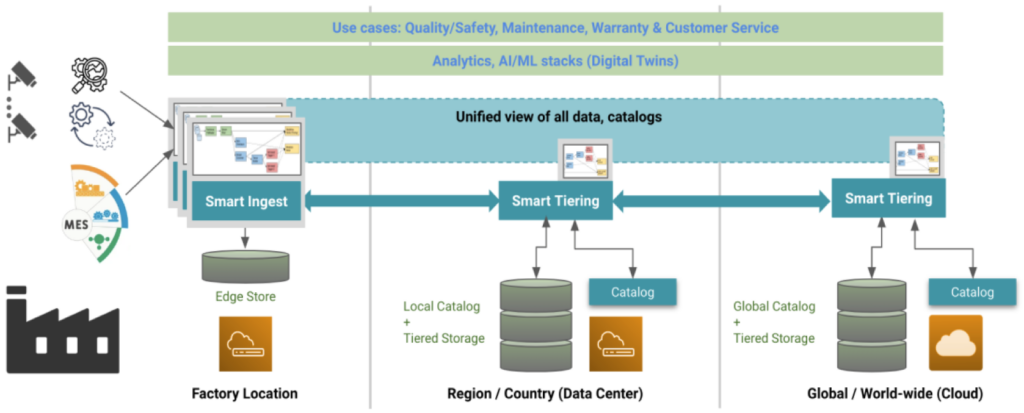
Smart Tiering efficiently stores and transfers massive datasets using policy-based tiering, reducing costs while improving access times for manufacturing workflows.
Akridata automates data validation, transformation, and prioritization using workflows. It captures relevant subsets of data and transfers them efficiently to reduce resource consumption and accelerate analytics.
Deploy across on-premises, hybrid, or fully cloud-based infrastructures to meet manufacturing needs.
Yes, it supports petabyte-scale data with flexible tiering and metadata-driven access.
Akridata uses user-defined schemas for cataloging and indexing data, enabling rapid retrieval of subsets based on attributes like timestamps, sensor types, or usage.