Akridata Named a Vendor to Watch in the IDC MarketScape for Worldwide Data Labeling Software Learn More
Transform ADAS/AV Data Ingestion with Akridata’s Cutting-Edge Platform
High-Volume Edge Data Ingest For ADAS/AV

The Issue
Data Challenges in Autonomous Systems
ADAS (Advanced Driver Assistance Systems) and Autonomous Vehicles (AV) produce terabytes of sensor data daily, creating challenges in:
- Data Collection: Prioritize relevant data for analytics, accelerating decision-making.
- Data Transfer: Reduce manual intervention by automating data transformation and tagging.
- Data Processing: Leverage distributed storage and intelligent processing to optimize resource usage
Why It Matters:
Without efficient ingestion and processing pipelines, businesses face:
- Long delays in data availability for model training.
- Increased costs due to redundant processing.
- Reduced productivity of engineering teams.
Why Efficient Edge Data Ingestion Is Crucial
Understanding the Requirements of ADAS/AV
To enable real-time decision-making and continuous improvement in autonomous systems, efficient data ingestion solutions are essential for:

Data Offloading
Handling data across multiple drives, with up to terabytes per trip.

Data Synchronization
Aligning cross-stream sensor data for analytics pipelines.

Data Enrichment
Tagging and curating relevant subsets for machine learning tasks.
The Akridata Solution
Smart Edge Processing for Scalable Data Ingestion
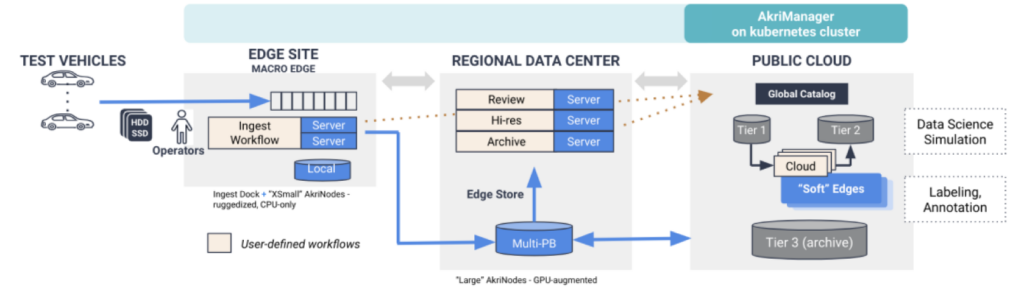
Akridata’s Edge Data Platform simplifies data collection, transformation, and transfer:
- Near Real-Time Validation Detect and correct faulty drives early.
- Event-Based Triggers Capture only the most relevant subsets (e.g., specific road types, weather conditions).
- Automated Data Transformation Convert proprietary data formats into standardized formats for faster downstream analytics.
- Cost-Efficient Data Tiering Prioritize data transfer to edge, intermediate datacenters, or cloud locations based on need.
Key Features of the Akridata Edge Data Platform
Streamlining Data Workflows for Maximum Efficiency
Cross-Stream Synchronization
Align multiple sensor data streams (LIDAR, GPS, RADAR).
Edge-Centric Workflows
Process data closer to the source, reducing latency and transfer costs.
Flexible Deployment Optionn
Scale across edge devices, datacenters, or public cloud environments seamlessly.
Customizable Workflows
Centralized workflow management ensures version control and consistency.
Deployment Benefits
How Akridata Accelerates Your Operations
- 10x Faster Data Access: Prioritize relevant data for analytics, accelerating decision-making.
- 2x Team Productivity: Reduce manual intervention by automating data transformation and tagging.
- 40% Cost Reduction: Leverage distributed storage and intelligent processing to optimize resource usage
Trusted By Leaders in Technology
Partner with industry leaders who rely on Akridata to
- Optimize AI model training pipelines.
- Streamline data workflows for autonomous systems.
- Reduce operational costs while maintaining high performance.
FAQs
Edge data ingestion refers to the collection and processing of data closer to the source (e.g., test vehicles) before transferring it to data centers or cloud environments. It is essential for reducing latency, improving efficiency, and enabling real-time insights for ADAS/AV systems.
Akridata automates data validation, transformation, and prioritization using workflows. It captures relevant subsets of data and transfers them efficiently to reduce resource consumption and accelerate analytics.
Yes, Akridata supports multi-petabyte scale data across distributed systems, from edge sites to cloud environments, ensuring cost-effective scalability and performance.
Using event-based triggers (e.g., GPS locations, specific driving scenarios), Akridata captures and processes only the most critical data for analytics and model training, minimizing unnecessary storage and processing.
The platform can be deployed across edge nodes, regional data centers, or cloud environments, providing flexibility for diverse infrastructure needs and use cases.

