We live now in an era where AI is everywhere around us, where applications and services rely heavily on automated systems with an AI-based component embedded in them. In order to perform well, these systems rely on getting an accurate output from various ML models, and while researcher and DS teams work tirelessly to improve models’ accuracy, understanding prediction accuracy is a tricky process. Factors like model complexity, the efficacy of model evaluation techniques, data bias and fairness, and the quality of data all impact prediction accuracy.
In particular, messy, low-quality data can throw a wrench into the accuracy of model predictions, especially when it comes to visual data sets. Visual data quality is often muddied up by common factors like data noise, misleading imaging, occlusion, and duplicates, and ultimately lead to a negative impact on model prediction accuracy.
While researchers and scientists have traditionally focused on improving the model to improve prediction accuracy, the data-centric AI approach shifts the focus on improving data quality to improve model prediction accuracy. When using clean, high-quality data from the onset, models have a better chance at performing optimally and offering the most accurate predictions. A clean dataset paves the road to successful algorithms, models, and prediction accuracy.
This is why tools like Data Explorer’s Saliency Maps are so critical to data scientists today.
Data Explorer’s Saliency Map benefits
Data Explorer is an AI platform that saves hours on visual data curation and reduces overall development costs. Following the data-centric AI approach, it allows data scientist teams to focus on their data by easily exploring and cleaning it at a large scale.
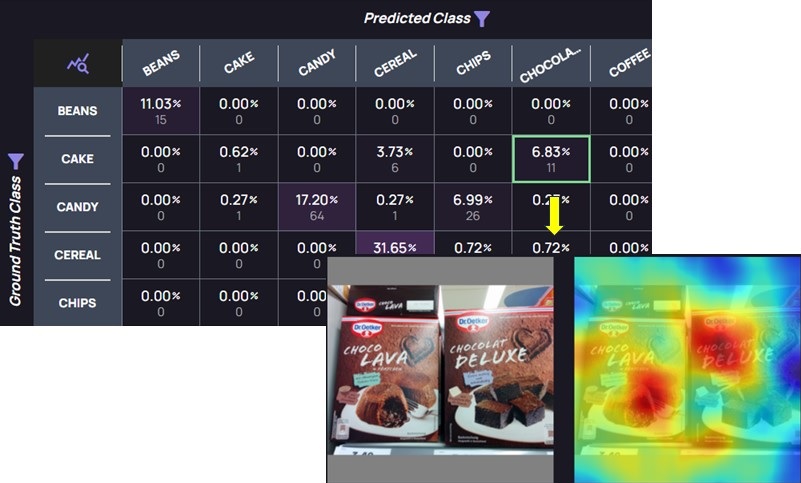
It’s often difficult to understand exactly how data is being analyzed by your model. Data Explorer’s Saliency Map solves this issue by allowing users to see the salient features of an image that influences your model’s inference, easily measure the spatial support of a particular class of an image regarding your computer vision models, and ultimately understand why your model predictions are incorrect.
Data Explorer allows users to analyze their model’s accuracy by providing tuneable confidence and IOU thresholds, along-side interactive common metrics, such as a confusion matrix and a PR-curve, all connected directly to the data, images, bounding boxes, classes and tags. This visualization is enhanced by providing saliency maps, allowing data scientists to understand which parts of the images affected the model’s decisions. This, in turn, can lead to informed decisions on how to improve the model’s accuracy.
As an example, consider an inaccurate classifier of a person’s actions. While the data appears to be clean, correctly labeled, diverse and balanced, the model is misfiring. Analyzing the incorrect predictions, and reviewing the saliency maps on selected images, it was immediately evident the model focused on a prominent, yet irrelevant part of the image. Simply cropping the image prior to the inference stage resulted in the expected accuracy from the model.
Once a model has been trained, saliency maps can be used to estimate its accuracy on new images and scenes – if the model bases its decision on irrelevant sections of the new images, it’s a warning sign that further training is required.
Get started with Data Explorer’s Saliency Maps
Ready to learn more about Data Explorer’s Saliency Maps and how Akridata can save your team’s time and resources while improving model precision accuracy?
To learn more, visit us at akridata.ai. Or register for a free account.



No Responses