Why Image Dataset Selection is Critical for Computer Vision Success
When working on computer vision tasks, the quality and selection of your image dataset can make or break your model. A well-curated, clean dataset paves the way to developing robust algorithms and systems. However, no matter how advanced your model or algorithm is, if the data is subpar, the output will be too—garbage in, garbage out.
But even with a clean dataset, a crucial question arises: Do you need to annotate and train on all the images?
The answer? Not necessarily!
Optimizing Image Datasets with Data Explorer
So, how do you determine which images to keep for training? This is where Data Explorer comes in. Data Explorer is a powerful platform designed to help you focus on your data, curate it effectively, and ensure that your development cycle starts with a solid foundation.
In previous blogs, we discussed how to visualize, explore, and use image-based search to find specific examples within a dataset. In this blog, we’ll dive into how to automatically select a subset of images for training—based solely on the images themselves, with no metadata or prior knowledge required.
Akridata Data Explorer Sampling Methods
Akridata Data Explorer offers six distinct sampling methods to optimize your image dataset for training computer vision models:
- Inlier Sampling: This method selects images similar to a cluster of points, focusing on the core data points that represent the primary patterns in your dataset.
- Outlier Sampling: Outlier sampling picks images dissimilar to all other points, helping you identify and include unique or rare data points that could provide valuable insights.
- Bimodal Sampling: Bimodal sampling selects strong inlier or outlier points, capturing both the main patterns and unique variations within the dataset.
- Normal Sampling: This method follows a normal distribution to select images, ensuring that your sampled dataset mirrors the natural distribution of your data.
- Uniform Sampling: Uniform sampling picks one sample after every ‘n’ samples, evenly distributing the selected data points across the entire dataset.
- Coreset Sampling: Coreset sampling selects a representative sample that attempts to preserve the cluster structure in the data, ensuring that even small clusters are represented after sampling.
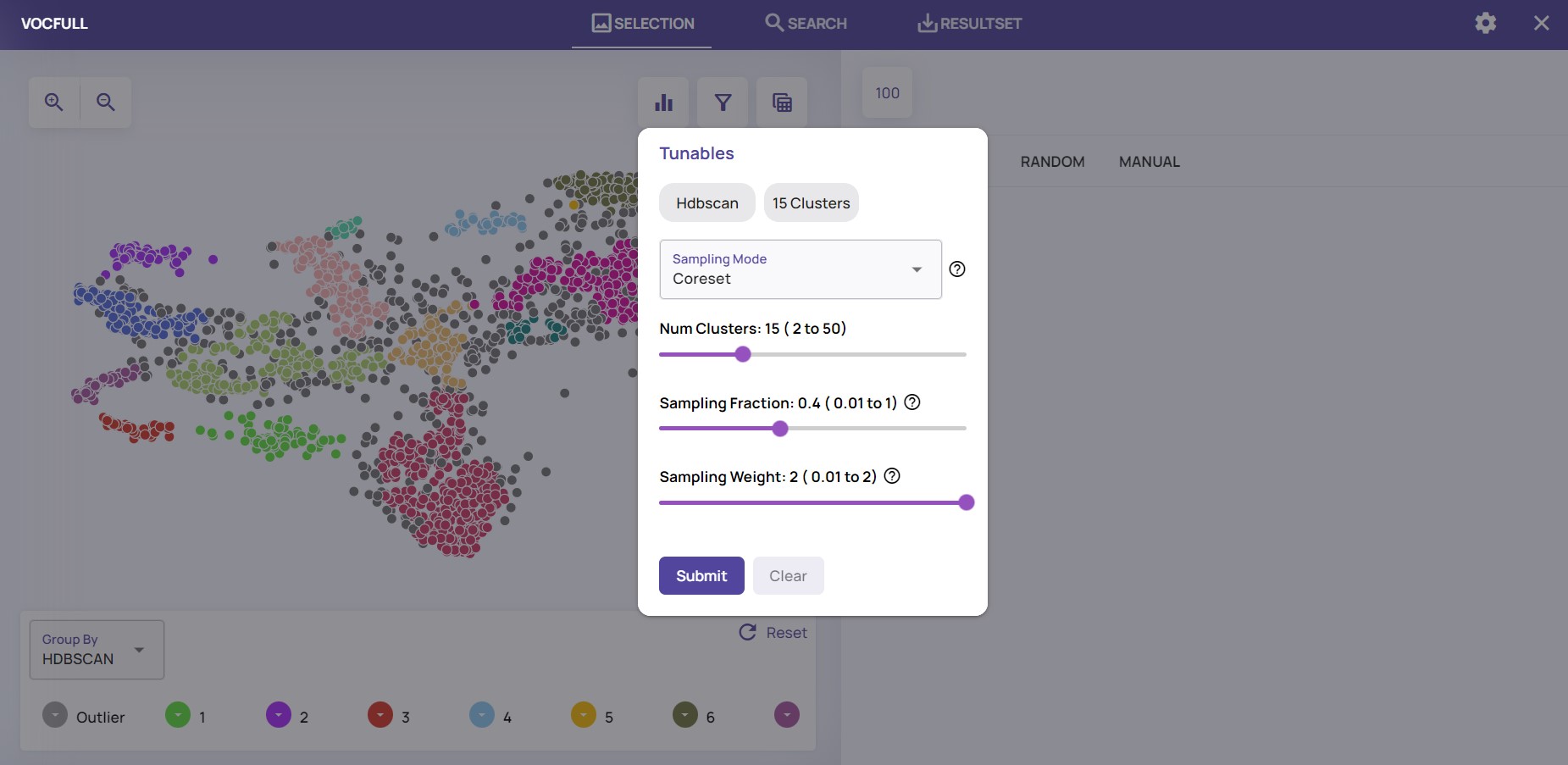
Applying any of these methods is straightforward. Simply click the “filter” icon, choose the relevant sampling method, and decide how much of the data you want to keep.
For instance, in the example below, you can see how easy it is to retain 40% of the images using the “coreset” option:

Click the “Filter” icon, then choose sampling method; sampling fraction — how much of the data to keep
Choosing the best option and what amount of data to keep depends on many factors, but Data Explorer provides a very simple interface to conduct various experiments.
The Coreset option tries to preserve the data structure, so even small clusters should be represented after sampling the data. As such, it may a good place to start the process.
Benefits of Image Dataset Sampling
Selecting a subset of images for training offers several advantages for computer vision tasks:
- Reduced Annotation Costs: By choosing only a portion of images for training, you can significantly reduce the time and cost required for annotating the entire dataset.
- Improved Training Efficiency: Training on a smaller, well-selected subset shortens training cycles, allowing for quicker iterations.
- Enhanced Model Accuracy: Sampling methods like coreset sampling help maintain the dataset’s structure, ensuring even small clusters are represented, which can lead to better model performance.
- Focused Data Curation: Sampling enables you to concentrate on the most relevant data points, making the dataset more manageable and effective for training purposes.
Akridata Data Explorer simplifies the application of these sampling methods, ensuring a more efficient and effective data curation process that leads to better outcomes for your computer vision projects.
Summary
In this blog, we explored how to choose and sample a subset of images from your dataset for training. By doing so, you can reduce annotation costs, improve training efficiency, and potentially enhance model accuracy—all while saving time and resources.
Stay tuned for future blogs, where we’ll discuss how Data Explorer leverages metadata to prepare the optimal dataset for the next steps in your development process.



No Responses