In today’s data-driven world, businesses rely on data science to transform raw data into valuable insights. However, the process of cleaning, analyzing, and extracting insights from data is complex. This is where a structured pipeline for data scientists becomes crucial, offering a framework for handling data through various stages, ensuring efficiency and consistency.
In this blog, we’ll break down the components of a data science pipeline and how it converts data into insights that support better decision-making.
What Is a Data Science Pipeline?
A data science pipeline is a series of steps, some could be automated, others semi-automated, to process data from its raw state to a final, usable output, often in the form of insights or machine learning models. Each step in the pipeline performs a specific task, from ingesting data and cleaning it to deploying a trained model. This structured process helps streamline workflows, reducing errors and saving time, particularly in projects requiring regular or large-scale data processing.
Why Pipelines Matter in Data Science
Data science pipelines are essential for several reasons:
- Efficiency: Pipelines automate data processing tasks when possible, saving time and reducing manual effort.
- Consistency: With a standardized pipeline, data undergoes the same process each time, minimizing inconsistencies.
- Scalability: Pipelines allow data processing to scale, making it easier to handle large volumes of data or complex analyses.
- Reproducibility: Pipelines create a repeatable process, making it easier to validate results or reproduce insights for future use.
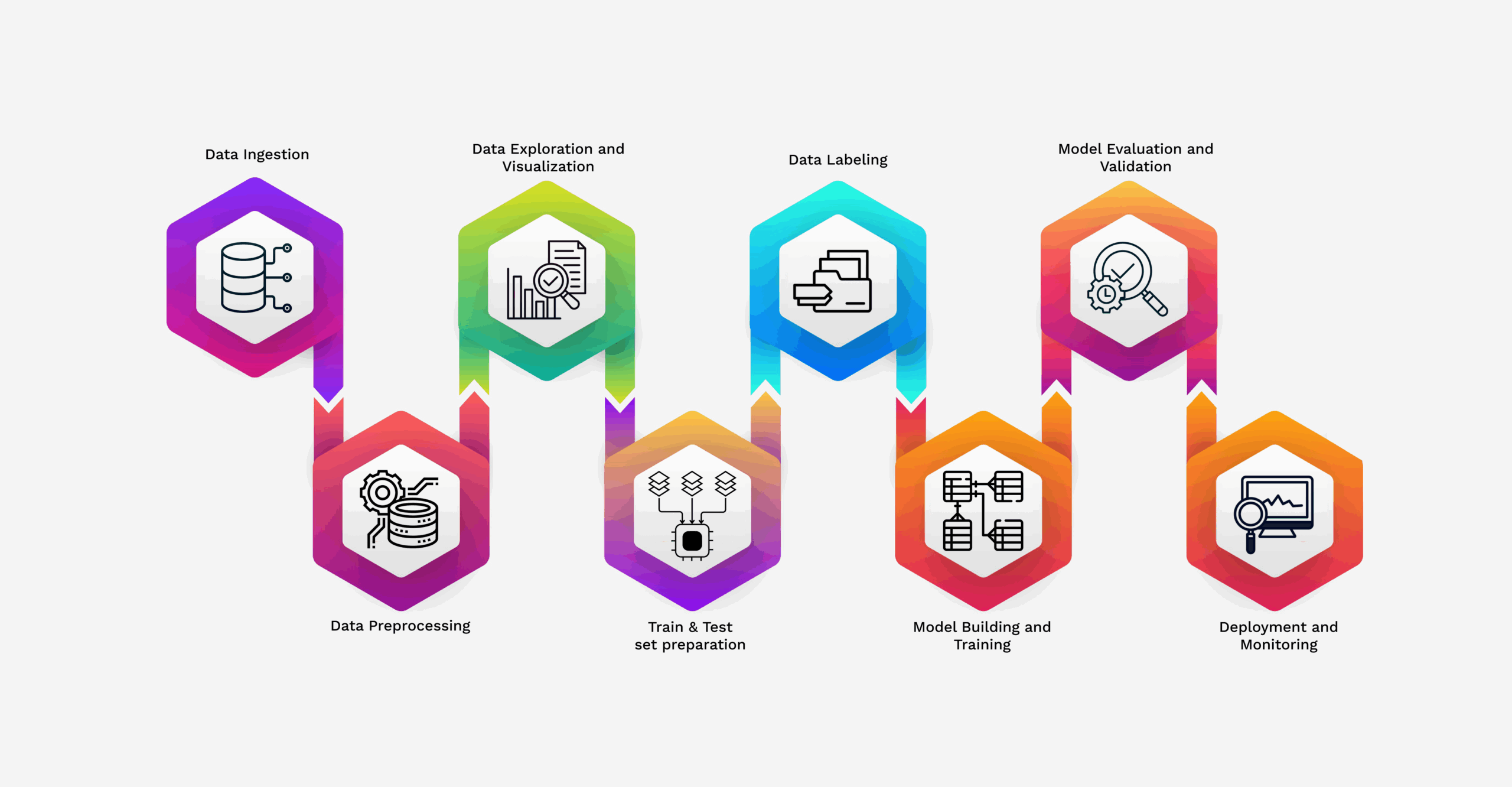
Key Stages of a Data Science Pipeline
The data science pipeline is typically divided into distinct stages. Let’s explore each of these stages in detail and how Akridata saves time for our users.
1. Data Ingestion
Data ingestion is the first step, where raw data is collected from various sources, including databases, APIs, web scraping, or IoT devices. This stage may involve pulling data in batches or streaming it in real time. The goal is to gather all relevant data to analyze later in the pipeline.
Akridata supports clients who wish to install cameras of various types for data acquisition, and the software to analyze the recorded videos or captured images.
2. Data Preprocessing
Once data is ingested, it goes through cleaning and preprocessing. This step is crucial because raw data often contains errors, inconsistencies, or missing values that can affect analysis. Data cleaning involves handling missing values, removing duplicates, and correcting errors. Preprocessing includes formatting, encoding categorical variables, and normalizing or scaling features to ensure compatibility with machine learning models.
Akridata offers prebuilt preprocessing options with custom steps available as needed. The data will be acquired into a centralized location on the cloud or a local server. Naturally, this step could be fully automated based on client’s requirements.
3. Data Exploration and Visualization
With clean and transformed data, the next step is exploration and analysis. This stage helps data scientists understand data patterns, distributions, and relationships. Exploratory Data Analysis (EDA) often involves data visualization and statistical analysis to identify trends or anomalies.
4. Data cleaning and Train & Test set preparation
Data is available – but is it ready? Usually the answer is no. Irrelevant or incorrect sets of images or videos, missing or incorrect labels, duplications and other issues related to the quality of the data can damage the final system’s output. Relevant images should be used for labeling purposes, then for training purposes, with a high quality dataset to be curated and then split into a training and a testing subsets.
Akridata allows you to do just that. First, focus on the relevant subset of images or videos – remove the irrelevant scenes based on the visualization, then use Text or Image based searches to find the relevant images or objects or even video snippets. Search on the full dataset or first apply smart sampling – on a real dataset, it was shown that with our Coreset selection mechanism, choosing 40% of the data achieved almost the same final mode accuracy, both at ~79%.
These steps will eliminate outliers, duplications and surface the relevant images.
Once a clean set of videos or images has been chosen, split it between a train and a test subsets – make sure there is no data leakage between the two, otherwise your model’s performance in production will be much lower than expected.
5. Data Labeling
After data has been curated, labeling is essential to make it useful for model training and testing. These labels will be used as ground truth, to which the model’s output is compared.
Akridata provides services to label the data based on clients’ specifications.
6. Model Building and Training
Once the data is ready, it’s time for model training. This stage involves selecting the right model(s), training them, and tuning hyperparameters. Naturally, the first step is to select a model that solves your problem, works well with your hardware, can be trained at a relevant cost and one that’ll be fast enough during inference.
Akridata offers several models for our clients to train, and we also develop custom models when needed. We support models for Classification, Object Detection, Segmentation and other tasks.
Training with Akridata requires no coding, all done through our UI, but for those who want, we offer an SDK and a python API.
7. Model Evaluation and Validation
Model evaluation is a critical step where the model’s performance is tested using metrics like precision, recall, or F1 score. Validation techniques like cross-validation and others are used to confirm that the model generalizes well to new data and isn’t overfitting or underfitting.
Akridata offers the above metrics, along side confusion matrices, PR curves and other ways to evaluate your models, based on an interactive UI to select parameters, like the IOU threshold for an object detector, where each correct/incorrect prediction is related to the data directly so you can see the images + labels.
That type of visualization allows you to identify gaps in the data, missing labels or model errors to be fixed in the next training cycle.
8. Deployment and Monitoring
Once the model meets performance requirements, it’s deployed to a production environment where it can generate predictions on live data. Monitoring is essential post-deployment to ensure the model remains accurate over time. Retraining or adjusting the model may be required when data or conditions change.
Akridata works with docker containers to wrap the models and provide a clean interface for running them. We can provide our dashboard for inspection line overview so production managers can see the big picture in real time.
Best Practices for an Effective Data Science Pipeline
- Define Objectives and KPIs Early: Clearly outline the goals of your data pipeline, focusing on the specific insights or outcomes you want to achieve.
- Modularize Pipeline Components: Break down the pipeline into reusable components, allowing for easier updates and maintenance.
- Automate Monitoring: Implement automated alerts for model drift or performance issues, so issues can be addressed proactively.
- Document the Pipeline: Proper documentation ensures that all stages of the pipeline are understandable and repeatable for future projects or team members.
Conclusion
Data science pipelines are fundamental for transforming raw data into actionable insights, enabling organizations to make informed decisions based on reliable, processed data. By ingesting & cleaning the data, prior to training cycles, data science workflows become more efficient, scalable, and reproducible.
Akridata provides tools and works with you to save time for each step throughout the journey of building a vision based system.



No Responses