Introduction
Object detection has become a cornerstone in computer vision, enabling machines to not only identify what’s in an image but also where it is. From autonomous driving to manufacturing quality control, object detection is transforming industries. However, training robust object detection models can be a complex and time-consuming task.
That’s where Akridata comes in. With our interactive no–code approach we simplify the model training process, allowing teams to accelerate development and focus on outcomes, not infrastructure.
What is Object Detection?
Object detection is a computer vision task that involves identifying and localizing objects within an image or video. Unlike image classification, which only assigns a label to an image as a whole, object detection provides bounding boxes and class labels for each detected object.
For example, in a single image, an object detection model could identify multiple objects such as cars, pedestrians, and traffic signs, each marked with its own bounding box.
Object Detection vs Classification
| Feature | Classification | Object Detection |
| Output | Single label for the whole image | Multiple labels with coordinates |
| Purpose | Identify what is in an image | Identify what and where in an image |
Prominent Object Detection Models
Let’s dive into some popular object detection models used today:
1. YOLO (You Only Look Once)
One of the most popular object detection models, the YOLO family of detectors offers real-time performance with high accuracy. YOLO divides the image into a grid and predicts bounding boxes and probabilities in a single pass.
YOLO has multiple versions, dating from a decade ago to the latest in 2025.
2. Faster R-CNN
Faster R-CNN improves upon earlier R-CNN versions by introducing a Region Proposal Network (RPN), which makes object detection much faster and more efficient.
3. SSD – Single Shot Detector
SSD is another real-time object detector that balances speed and accuracy. It uses default boxes of different aspect ratios and scales to detect objects.
Post-Processing with Non-Maximum Suppression (NMS)
Object detection models often produce multiple bounding boxes for the same object. To address this, a technique called Non-Maximum Suppression is used.
How it works:
- Rank all predicted boxes by their confidence scores
- Select the box with the highest score
- Remove boxes that overlap significantly, using IoU – Intersection over Union
- Repeat until all boxes are processed
NMS ensures that each object is detected only once, providing cleaner and more accurate results.
Akridata’s Model Training Flow
At Akridata, we believe that building vision AI systems should be more about iteration and insight, and less about infrastructure and guesswork. Our interactive no–code approach is designed for rapid experimentation and user-friendly workflows.
Key Features:
1. Split Data into Train–Validate–Test Quickly navigate through image datasets and associated metadata. Interactively and quickly build clean and curated Train, Validation and Test sets. No leaks between the three and no overlaps.
2. Metadata Review Review the existing metadata, i.e. labels & bounding boxes, and use our Auto–label to complete your training setup when metadata is missing.
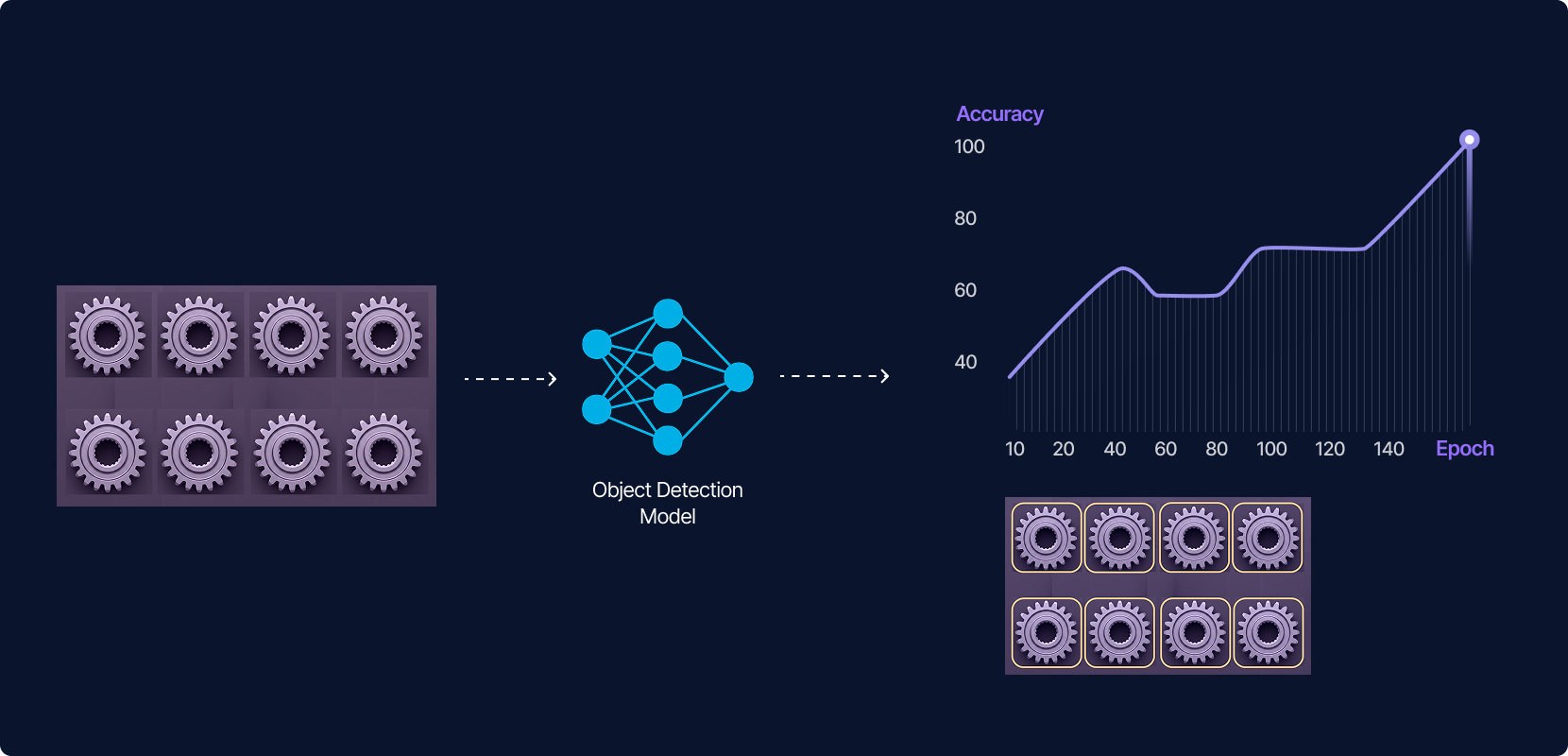
3. Model Training Run training jobs directly from the UI: choose one of several models, select number of epochs and other hyperparameters or leave it all to us. The model trains and you can follow the accuracy until it converges. Run multiple experiments and track performance metrics, adjust hyperparameters, and visualize outputs.
4. Evaluation & Comparison Tools Compare multiple model versions side-by-side with visualizations, confusion matrices, and performance metrics.
5. Seamless Feedback Loop Feed insights back into the labeling and training process, all within a single platform.
Conclusion
Object detection is powerful but complex. From managing large datasets to tuning models and evaluating results, there’s a lot that can go wrong.
With Akridata’s interactive approach, teams can:
- Train models faster
- Iterate more efficiently
- Gain deeper insights into performance
Whether you’re building a proof of concept or deploying to production, Akridata simplifies the journey from data to decision.
Ready to take your object detection workflows to the next level? Try Akridata today.



No Responses