In deep learning, having a large, diverse dataset is crucial for training high-performing models. However, gathering extensive data can be costly and time-consuming. This is where data augmentation in deep learning comes in, offering a cost-effective way to expand and diversify training datasets. By applying a variety of transformations to the existing data, data augmentation enables models to generalize better, resulting in higher accuracy and robustness.
This blog will delve into popular data augmentation techniques in deep learning, demonstrating how these methods enhance model performance by simulating a more diverse dataset.
What is Data Augmentation in Deep Learning?
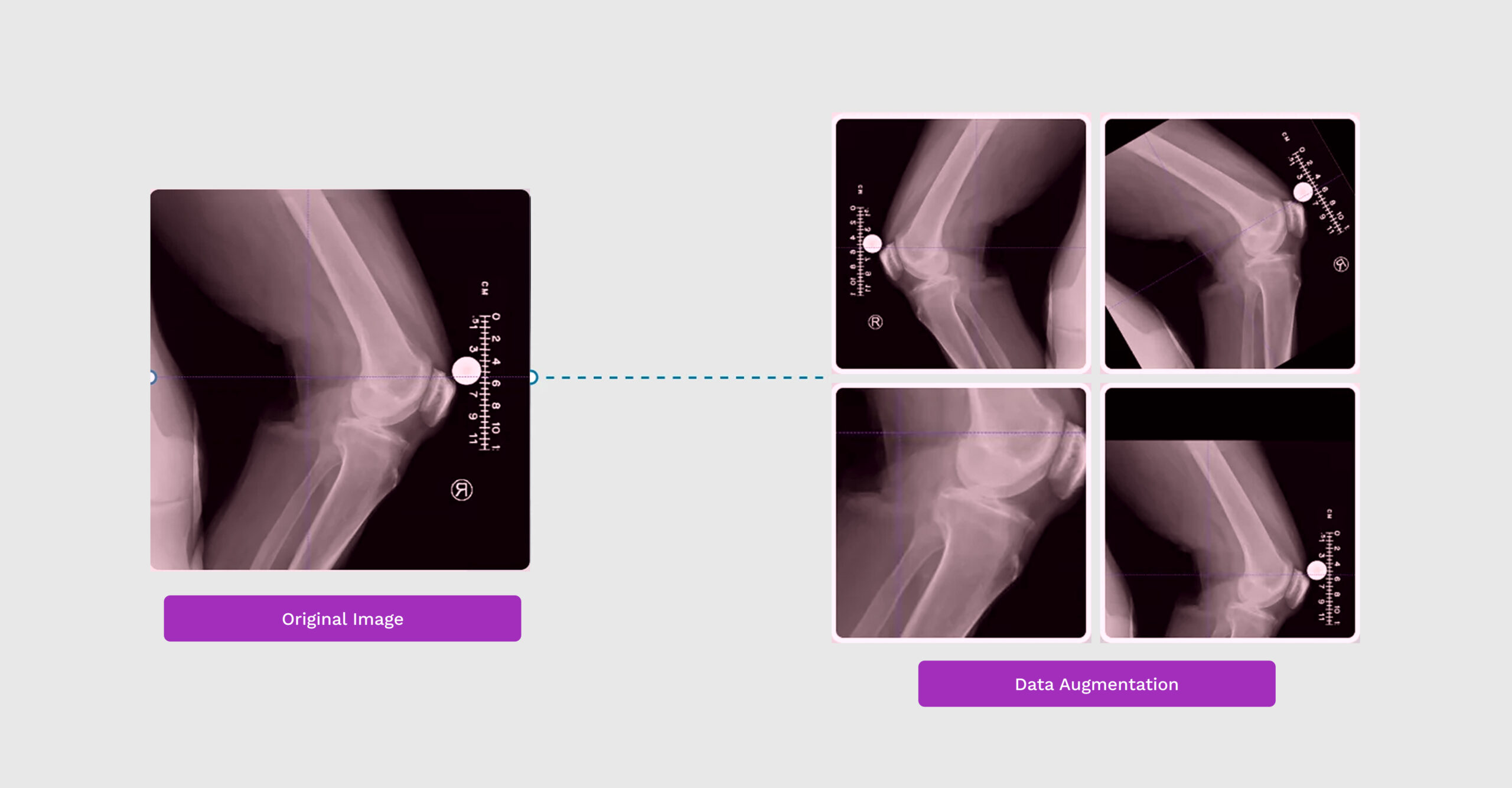
Data augmentation is the process of creating new training samples by applying transformations to the existing dataset. In deep learning, data augmentation is particularly beneficial in computer vision tasks where models learn from image-based data. Techniques such as rotations, flips, scaling, and color adjustments introduce variability, allowing models to handle diverse inputs and reducing the risk of overfitting.
Data augmentation can be applied in real-time during training or as a pre-processing step, enabling a model to learn generalized patterns across a wider range of scenarios.
Benefits of Data Augmentation in Deep Learning
- Improves Model Generalization
By training on augmented data, models learn to recognize patterns across different variations, improving generalization and reducing overfitting. - Compensates for Small Datasets
For domains where data is scarce, data augmentation creates additional training samples, enhancing model accuracy without needing new data collection. - Enhances Model Robustness
Introducing variations, such as brightness changes or rotations, helps models perform better on real-world data with natural variations.
Common Data Augmentation Techniques for Images
- Geometric Transformations
Geometric transformations include operations like rotation, flipping, cropping, and scaling, which alter the orientation or dimensions of the image while preserving its essential features.- Rotation: Rotating images by a random angle (e.g., 0–30 degrees) ensures the model learns to recognize objects from different angles.
- Flipping: Horizontal and vertical flips are effective for datasets where object orientation does not impact recognition, such as natural images or symmetrical objects.
- Scaling: Zooming in or out allows models to recognize objects at varying distances.
- Cropping: Random cropping simulates viewing objects from different perspectives, ensuring the model focuses on different image regions.
Example: In a dataset of cats and dogs, rotating images slightly allows the model to recognize animals regardless of the angle they’re positioned.
- Color Space Adjustments
Changing color properties like brightness, contrast, saturation, and hue encourages the model to recognize objects under different lighting conditions or environments.- Brightness Adjustment: Randomly darkening or brightening images prepares the model for real-world lighting variations.
- Contrast Adjustment: Enhancing or reducing contrast helps the model distinguish features in low-contrast images.
- Hue and Saturation Changes: Altering color tones helps the model generalize across different lighting conditions or environments.
Example: In medical imaging, brightness adjustments help models detect features in images with varying lighting or exposure conditions.
- Noise Injection
Adding random noise to images can improve model robustness, especially in environments where images might contain distortions or imperfections. Common noise types include Gaussian noise and speckle noise.
Example: Noise injection is useful in autonomous driving applications where camera sensors may capture noisy images due to environmental factors like fog or rain.
Tools for Data Augmentation in Deep Learning
Several popular libraries offer ready-to-use augmentation techniques for deep learning:
- PyTorch, TensorFlow and Keras: All support image data augmentation layers like rotation, flipping, and zoom.
- Albumentations, imgaug: Other Python libraries for image augmentation.
Choosing the Right Data Augmentation Techniques
Selecting appropriate augmentation techniques depends on the task and dataset characteristics. Here are some considerations:
- Domain-Specific Needs: For instance, flips might be useful for natural images but not for text images.
- Real World Scenarios: Consider the edge cases and extreme real-world scenarios, and see if those can be achieved via data augmentation.
Data for Training with Akridata
Data augmentation is used to enrich a dataset for training a model, and making it more robust and accurate. Prior to the training step, Akridata allows our users to choose the most relevant images for training and testing their models and enrich it with synthetic data. Once ready, our training mechanism supports different data augmentation options for model training, thus resulting in robust and accurate models.
Conclusion
Data augmentation in deep learning is an essential tool for improving model performance, especially in situations where data collection is limited. By applying transformations that mimic real-world variability, data augmentation makes models more adaptable, resilient, and capable of handling diverse inputs.
Akridata allows you to select the most relevant images for model training & testing, and then uses the latest techniques for data augmentation during model training.



No Responses