Class imbalance-in-visual data sets is an all too common problem in real-world applications that use machine learning and AI.
Many applications of computer vision suffer from imbalanced class distribution, including fraud detection, anomaly detection, medical diagnosis, oil spillage detection, facial recognition, and more. The consequences of imbalanced class data can have serious impacts on model training, and more importantly on model performance.In this blog post, we will explore common questions about class imbalance in visual data sets, and answer the questions:
- What is class imbalance?
- What is a class imbalance in a visual data set?
- What causes a class imbalance?
- How does class imbalance affect model accuracy?
- What are common techniques used to address class imbalance?
- What is the best solution to solve class imbalance?
What is Class Imbalance?
A class is simply a grouping of data by some attribute (like appearance, functionality, or movement). A class imbalance is where a data set has skewed class proportions that don’t represent their occurrence in nature, meaning that any model built off this data will not give adequate weighting to under-represented classes, likely meaning poor performance when these situations are encountered.
Class imbalances are hard to avoid completely, as they occur naturally in data, but can be exacerbated by factors including dataset size, label noise, and data distribution; spotting them early is critical to controlling model accuracy.
What is a Class Imbalance in a Visual Data Set?
Visual data is data represented in a graphical, pictorial, or video format. In today’s AI and ML-dominated world, visual data could take the form of images, scans, traffic camera photos, aerial imagery, or 2D/3D Point clouds.
Visual data is increasingly prevalent in our society and used across a huge range of industries, including security, medical, automotive, construction, transportation, retail, and many more.
Unfortunately, class imbalance is a major issue for visual data sets, as skewed distributions of samples will improperly train models on the imbalanced data sets.
Imagine a medical lab is looking for image scans showing cancer cells, but it is predominantly showing only the left lung and underrepresenting the right lung. This can cause the model to predominantly focus on images for the left lung rather than the right leading to potential misses.
What Causes a Class Imbalance?
Class imbalance is a very common problem. Class imbalance occurs when there is an unequal distribution of classes in a training dataset.
When a machine learning algorithm assumes a data set is equally distributed, class imbalance becomes an issue. Frequently, the ML leans towards a bias of the majority, or dominant, class, and causes a poor classification of the minority class. In an extremely imbalanced data set, the minority class may even be completely ignored.
The end result? The model performs poorly on minority classes. This becomes a major problem, as the minority class usually offers the predictions that are most important.
How Does Class Imbalance Affect Model Accuracy?
The performance of AI models can be evaluated on multiple aspects, such as classification accuracy, object detection, segmentation, or landmark/keypoint detection, depending on the type of model.
For classification models, generally, they are evaluated on classification accuracy. If the accuracy of a model is above 90% accuracy, most will assume the model is accurate and performing well. However, if class imbalance has created a model where the majority class is favored above other data sets, then the performance of the model will not work as intended or needed. This is a classic issue that is more commonly known as the “Accuracy Paradox”.
Or, let’s put it this way. Most machine learning algorithms are designed to work best when each class has an almost or mostly equal number of samples. Class imbalance causes the model to only deliver an error-free and accurate return on the majority class, since the minority class has not been fully captured.
This becomes a big problem when it comes to real-world ML visual data applications, like cancer detection through organ scans. If a model only recognizes the majority class of certain images as potential signs of cancer, an incorrect diagnosis or delayed treatment could be the end result. For real-world applications, it’s clear that class imbalance can have serious consequences.
Techniques Used to Address Class Imbalance
There are multiple techniques that can be used to narrow the problem of class imbalance and achieve an appropriate data selection. These techniques include:
- Oversampling
- Undersampling
- Data Augmentation / Synthesizing
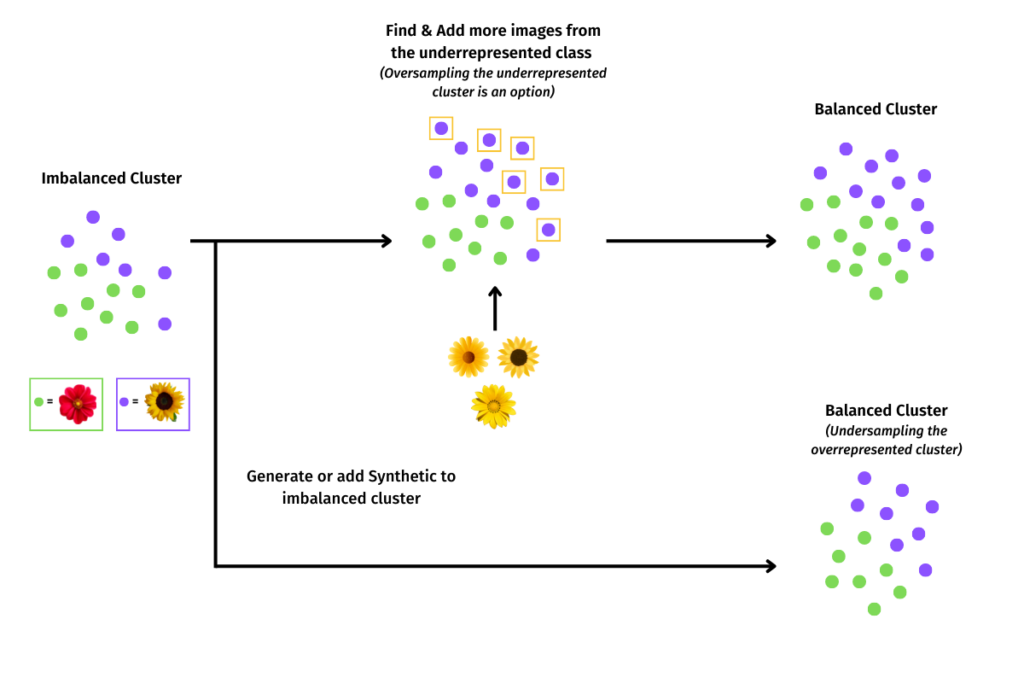
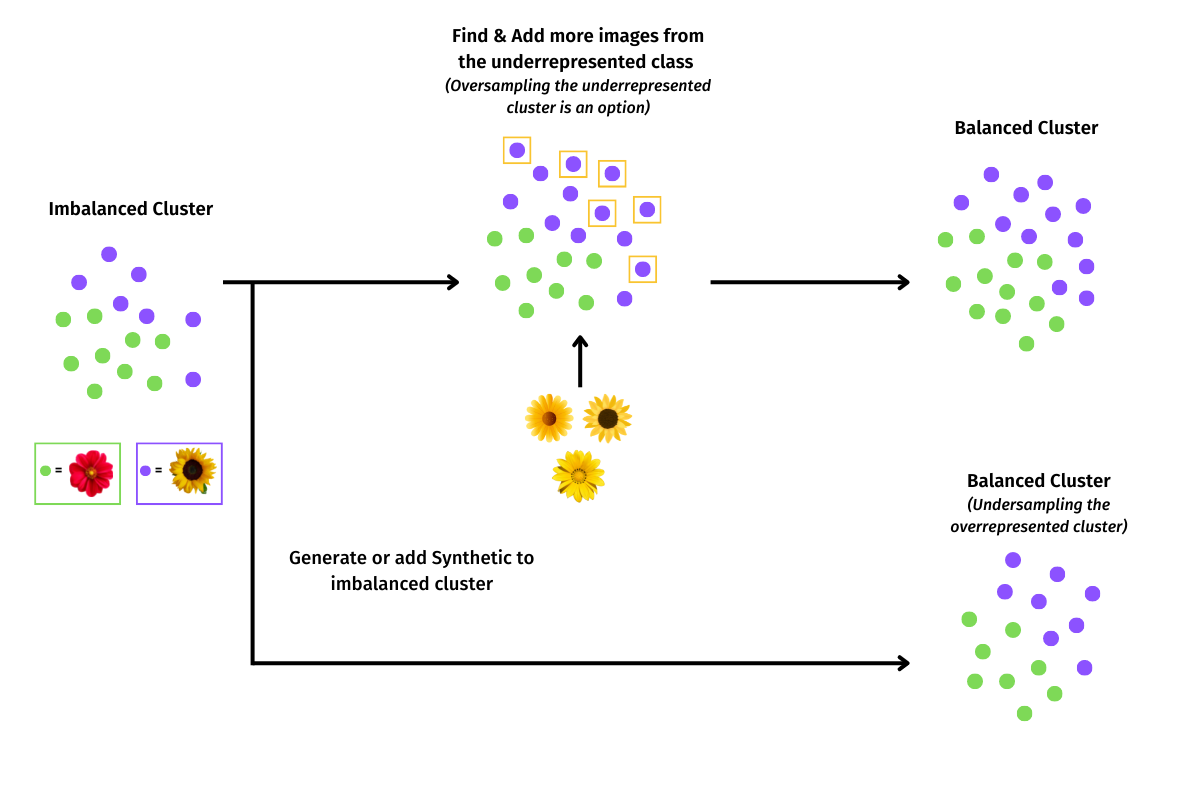
One of the most common techniques used to address class imbalance in visual data sets is to oversample the data. With this tactic, you must upsample or downsample the minority or majority class. By randomly oversampling and duplicating examples from the minority class into the training dataset, you can theoretically retrain the model to include the importance of the minority class data. This technique is most effective for algorithms where multiple duplicate examples from the minority class can influence the overall accuracy of the model.
Another technique used to address class imbalance is to undersample the data. Randomly undersampling the data involves randomly selecting examples from the majority class to delete from the training dataset, to match with the minority class. With this technique, you create a similar number of records present in the dataset, which theoretically creates equal balance and significance for both classes of data.
One can also opt to synthesize data to address class imbalance. This technique involves generating new data for underrepresented classes either using ‘data augmentation’ techniques (where existing data is processed and combined in interesting ways), or scenario-based ‘data synthesis’ techniques.
While randomly oversampling and undersampling the data are the two most common techniques used today to address class imbalance, resampling has two significant drawbacks.
First, oversampling the minority class can drive overfitting, which is when the model learns patterns that only exist in the oversampled sample. When the model fits perfectly against training data, the algorithm still cannot perform accurately against unseen data, which ultimately makes oversampling a self-defeating concept.
The second drawback to resampling the data, specifically undersampling the majority class, is that underfitting can occur. In underfitting, the model fails to capture the general pattern in the data. When a model is too simple, requires more training time, or less regularization, the model will still not be able to conclude dominant trends within the data. Again, the result is inaccurate and poorly performing applications.
What is the Best Solution to Solve Class Imbalance for Visual Data?
If you’re ready to solve the class imbalance issue in visual data sets, you’re ready for Akridata.
Akridata Data Explorer is a revolutionary AI platform built for exascale visual data and AI training.
Akridata is a decentralized data management and tiering software optimized for video, radar, and lidar data. Akridata runs on all resources, from edge to cloud, as a software blanket that provides structure and a scalable process to deliver curated, consistent, and relevant AI-ready data sets.
In order to reduce class imbalance quickly and efficiently, Akridata pre-processes, catalogs, and prioritizes unstructured data at the edge to uncover the most relevant data more quickly. Akridata’s Data Explorer makes it easy to visualize and quantify data drifts, identify and resolve class imbalances within ML, and adjust bias and de-bias in your training and test sets.
Additionally, Data Explorer can browse, search, and access specific data, at the edge, core, or cloud, regardless of geography, storage tier, version, etc. Whether it’s constantly changing data relevancy, evolving data pipelines, or inaccuracies in data, Akridata can handle it all.
While class imbalance is a common issue within visual data and AI applications today, Akridata is a first-in-class solution to train your AI models more effectively and correct class imbalance.



No Responses