Akridata Named a Vendor to Watch in the IDC MarketScape for Worldwide Data Labeling Software Learn More
High-Volume Edge Data Ingest For ADAS/AV
The Issue
Issue Statemtent
ADAS and Autonomous Vehicles (AV) generate several terabytes of data per day at th edge which poses unique set of problems. There is a need for a robust platform to ingest, process, transport and store data from the edge.
What exactly is the issue?
The Automotive industry vertical is going through a dramatic transformation.
Why?
Thanks to the emergence of increasing levels of driving autonomy in both personal and commercial use vehicles. These autonomous capabilities span the spectrum from L2/L3-level ADAS (Advanced Driver Assistance Systems) to L4/L5-level AV (Autonomous Vehicles). These capabilities are realized using perception and higher-level planning and routing algorithms that take as input data about the vehicle’s environment from a growing collection of rich sensors camera, LIDAR, and RADAR, which augment traditional telematics and log information (GPS, IMU, CAN bus, etc.) and external sources such as HD Maps and V2I/V2X platforms.
Successful development and production deployment of ADAS/AV perception and planning/routing algorithms require access to large volumes of real-world data from drives performed by test, validation, and production vehicles.
This data is collected from individual vehicle drives, often amounting to several Terabytes (TB) per vehicle per drive, and depending on the type of vehicle (test, validation, or production), is offloaded from the vehicle either using physical media (HDDs/SSDs or custom logging devices), or sent directly to the destination over cellular networks.
Independent of the mechanism, the collected vehicle data needs to be transferred to a data center or cloud environment where one can store the vast volumes of data in a cost-effective fashion, transform the data as required for analytics and perception model training tasks, enrich the data to create metadata, which is then used by model training and general analytics pipelines to retrieve the data.
The overall problem of managing the collection, transmittal, transformation, tagging, and retrieval of ADAS/AV data is complex because of multiple interrelated reasons — the geo-distributed nature of the source vehicles, the volume of data produced by each vehicle, and the shifting focus on the current most-relevant subset of the data (a function of how well the perception algorithm is performing and where its edge cases lie) — and the need to carry out all of the operations in a scalable, timely, and cost-effective fashion.
Existing solutions that attempt to collect and transmit all vehicle data to a central facility prior to running any data pipelines suffer from long delays (from data collection to data use), large resource needs (for data storage and analytics), and poor team productivity (to retrieve the data of most interest for a specific task).
The Akridata Solution
Akridata’s Edge Data Platform provides a comprehensive solution to the ADAS/AV data management problem.
Smart edge processing components enable data collection and transformation activities to start as close to data sources as possible (e.g., at a garage where the test vehicles arrive after their drives, or in certain cases, within the vehicle itself).
Edge Processing
- Allows data validation checks to be performed in near real-time (allowing remedial actions for faulty drives),
- Permits the early extraction of meta-data (to help prioritize data processing post transfer to the datacenter or cloud),
- Enables the raw sensor data to be transformed from potentially proprietary data formats into standard ones (or alternate representations such as a downscaled, low-resolution representation of image streams), together with cross-stream time synchronization to efficiently support downstream processing,
- Identifies the most relevant subsets of the collected sensor data using a flexible combination of event-based triggers (e.g., a certain log event, or a GPS location condition), custom scenario-detection modules (e.g., that look for a certain type of road and vehicle condition such as a puddle on the road), and statistical analyses (e.g., diversity-preserving ‘coreset’ sampling), and
- Handles the prioritized transfer of both the raw and transformed objects (e.g., most relevant data first) to multiple destination locations (including storage at the edge, an intermediate datacenter, or one or more cloud tiers) to ensure cost-effective placement and tiering.
The logic capturing all of the actions above is expressed in the form of programmable workflows, which represent processing pipelines built out of individual modules expressed in various languages. Workflows are centrally developed, can be conveniently and flexibly deployed to one or more edge locations, and can be integrated with CICD processes to provide consistent behaviors with version control. Together, the workflow-enabled smart edge processing supported by the Edge Data Platform enables a highly automated, efficient, and scalable data ingest process of the kind illustrated in the figure below, which represents an edge-datacenter-cloud deployment at a leading Auto OEM.
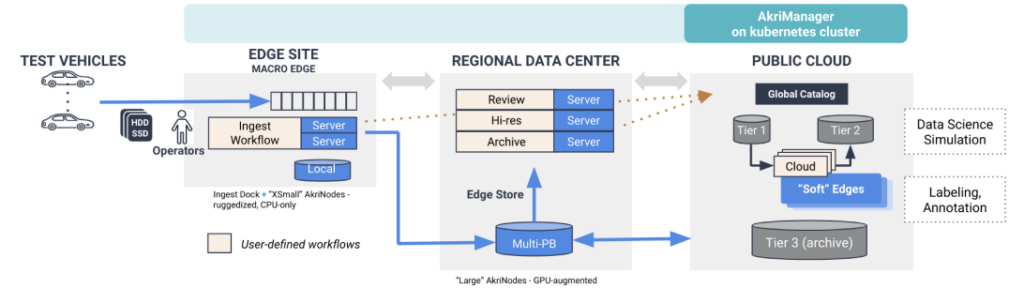
Characteristics of the deployment include:
- Ingestion of 1+ PB/month of sensor data (spanning multiple camera and LIDAR sensors), processed using ~30 workflows that carry out transformations from proprietary sensor types, various types of sensor fusion, and ML models for data enrichment.
- End-to-end visibility and control of the ingest process and workflow execution across the edge, data center, and cloud sites.
- Ability to isolate and protect the customer’s sensitive processing logic by constraining their use in workflows that are allowed to run only at customer-controlled edge sites and the regional data datacenter.
- Storage of the ingested data across the edge, data center and cloud storage tiers in a fashion that is optimized for cost, latency, and considerations of cross-site network BW and ingress/egress costs.
The deployment has helped the customer achieve:
- 10x faster access to relevant data — enabled by the at-source collection of vehicle data and prioritized transfer of the most relevant data,
- 2x productivity for data science and ML teams — by eliminating redundant processing of the raw sensor streams, and enabling efficient access to preprocessed intermediate representations
- 4x reduced infrastructure costs — by supporting the distributed and tiered storage of data without compromising on its on-demand unified access, and reducing compute resources for redundant processing.
Trusted By Leaders in Technology
Designed for Data Science teams to accelerate the path to building Production Grade AI models


Products
- © 2025 Akridata
- Privacy Policy
- Terms & Conditions