Loaded with intuitive and interactive features to tackle hard and time consuming problems
Connect
Virtually connect multiple data sources and associated meta-data databases to explore, search, and analyze visual data based on system-defined meta-data. Without the need to create copies of data and meta-data, analysis can always be conducted with the most up-to-date versions.
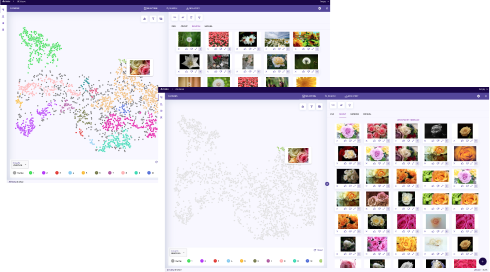
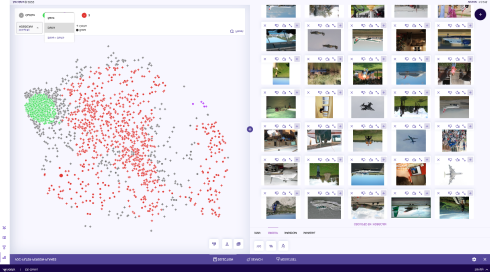
Explore
Explore visual data on unlabeled datasets by combining traditional meta-data-based filtering with content feature-based latent structure exploration to better understand the inherent clustering or segmentation structure in the data set.
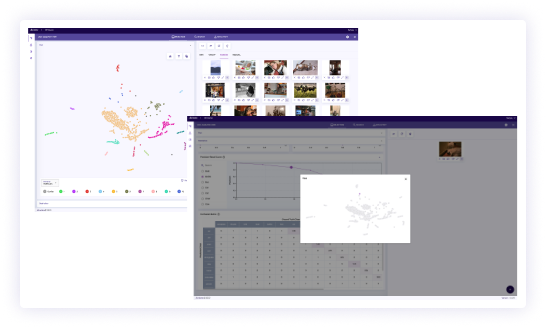
Search
Perform powerful image-based similarity searches on millions of images in seconds and then further refine the results through interactive scoring on a subset of data to search for domain-specific features by combining active search techniques.
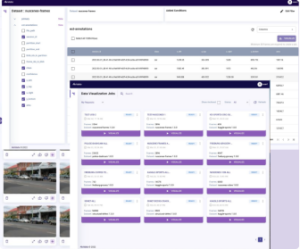
Analyze
View model performance from multiple lenses and an aggregate view to identify the causes of inaccuracies within your model by isolating and focusing on the data that matters.
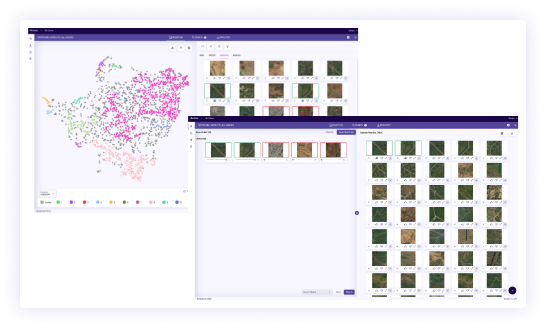
Compare
Identify novel data across multiple data sets to create more training points, evaluate labeling quality and consistency, determine data drifts, and more.
Benefits of using
Data Explorer
Save time and resources
Reduce hours of work to minutes. Drastically cut the manual labor and time spent on data selection and curation.
Accelerate the path to accuracy
Reduce the number of iterations and guesswork for improving your model accuracy by creating balanced and ...
Reduce the labelling spend
Avoid wastages in the costs associated with labeling data and get a better ROI on what you spend.
Selection of Data has a cascading effect on Training Time, Resources and achieving Model Accuracy.
Discover the power of
Data Explorer
Designed for Data Science teams to accelerate the path to building Production Grade AI models