Akridata
Akridata Named a Vendor to Watch in the IDC MarketScape for Worldwide Data Labeling Software Learn More
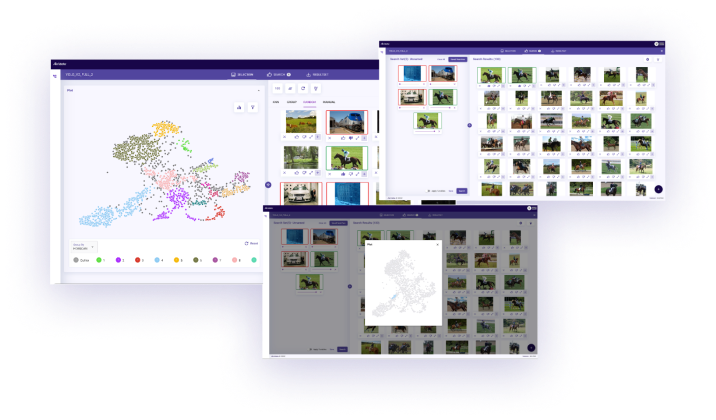
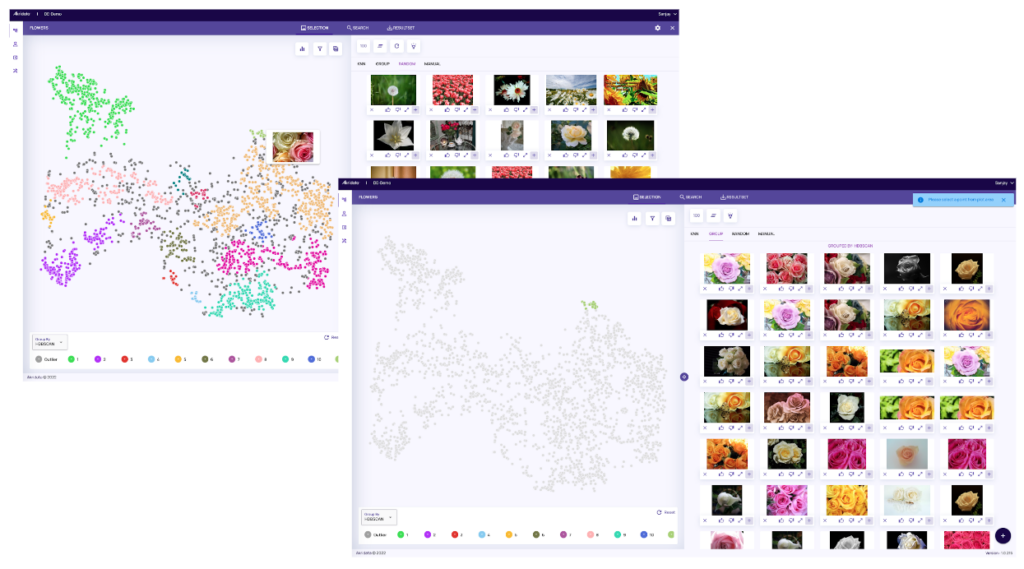
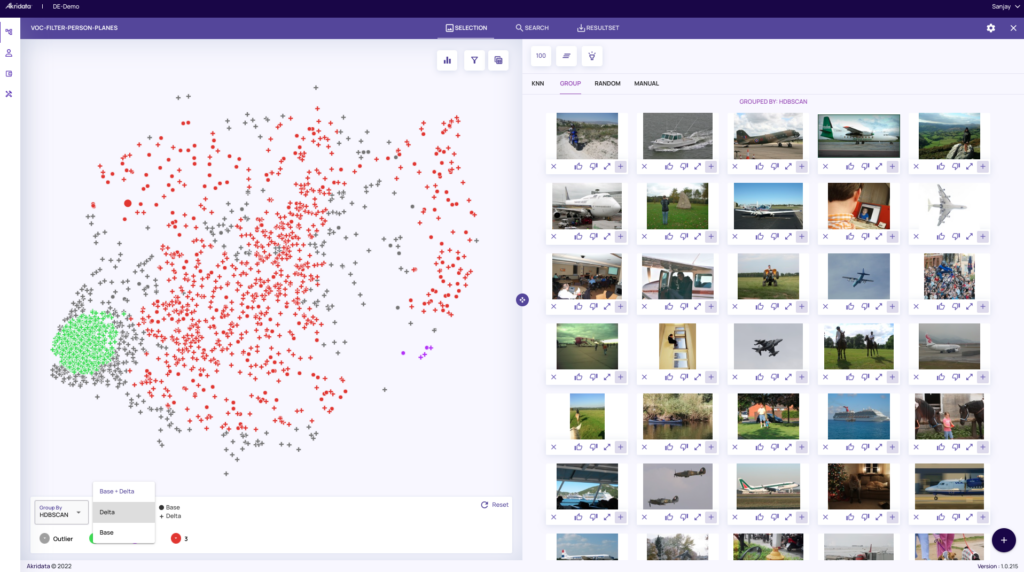
Understand the latent structure of the data in clusters based on feature embeddings
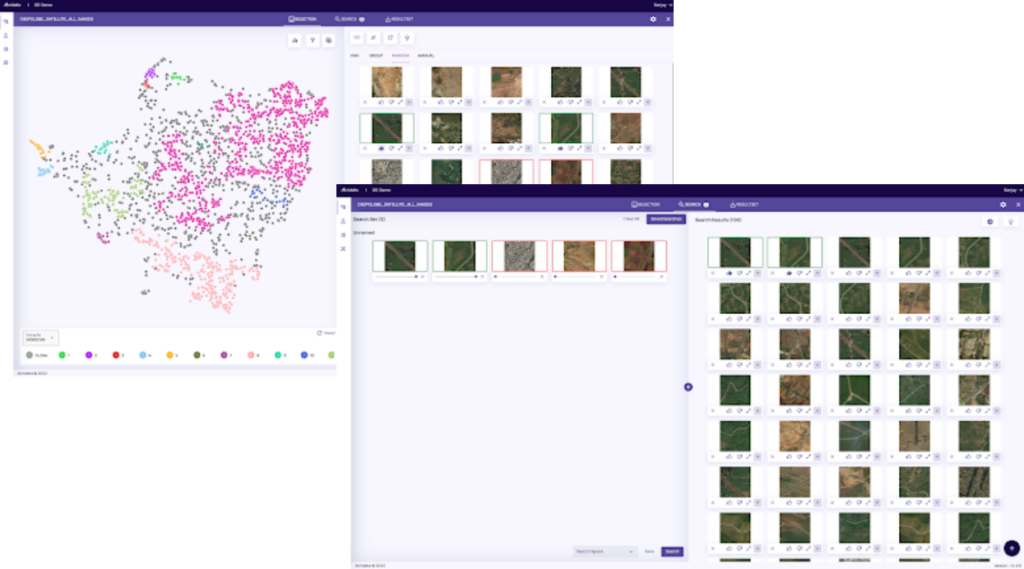
Intuitively search through the data for points of interest based on visual inputs
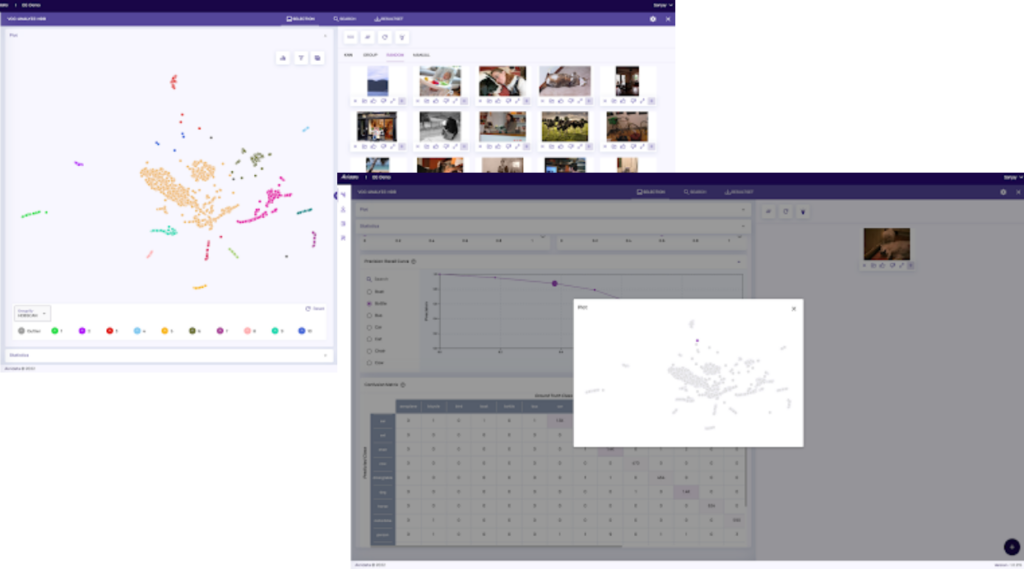
Root cause the problem of model accuracy by focusing on the data that matters
Quickly identify novel data across visual data sets
Reduce hours of work to minutes. Cut time spent on data selection and curation.
Avoid wastages in labelling spends. Get more for the $s you spend.
Accelerate your path to model accuracy. Reduce the iterations and guess work.