A dataset of images, used for computer vision tasks, could be the key to success or failure. A clean dataset could lead the way to a great algorithm, model and ultimately system, while no matter how good the model or algorithm is, garbage in – garbage out.
So, how do we know what we have? How do we make sure the data is clean, high quality, and contains what we really need?
If the dataset was small (ex. 100s of images), we could check it manually. Maybe, write scripts or code for random sampling and some statistics, exploration and tests. With larger datasets, or frequently new sets to review, this is not feasible.
Power of Data Explorer
Let’s see how Akridata’s Data Explorer
helps us. Data Explorer is a platform that was built to allow us focus on the data, curate it, clean it and make sure we start the development cycles with a great foundation. It will be handy in later stages of development too.
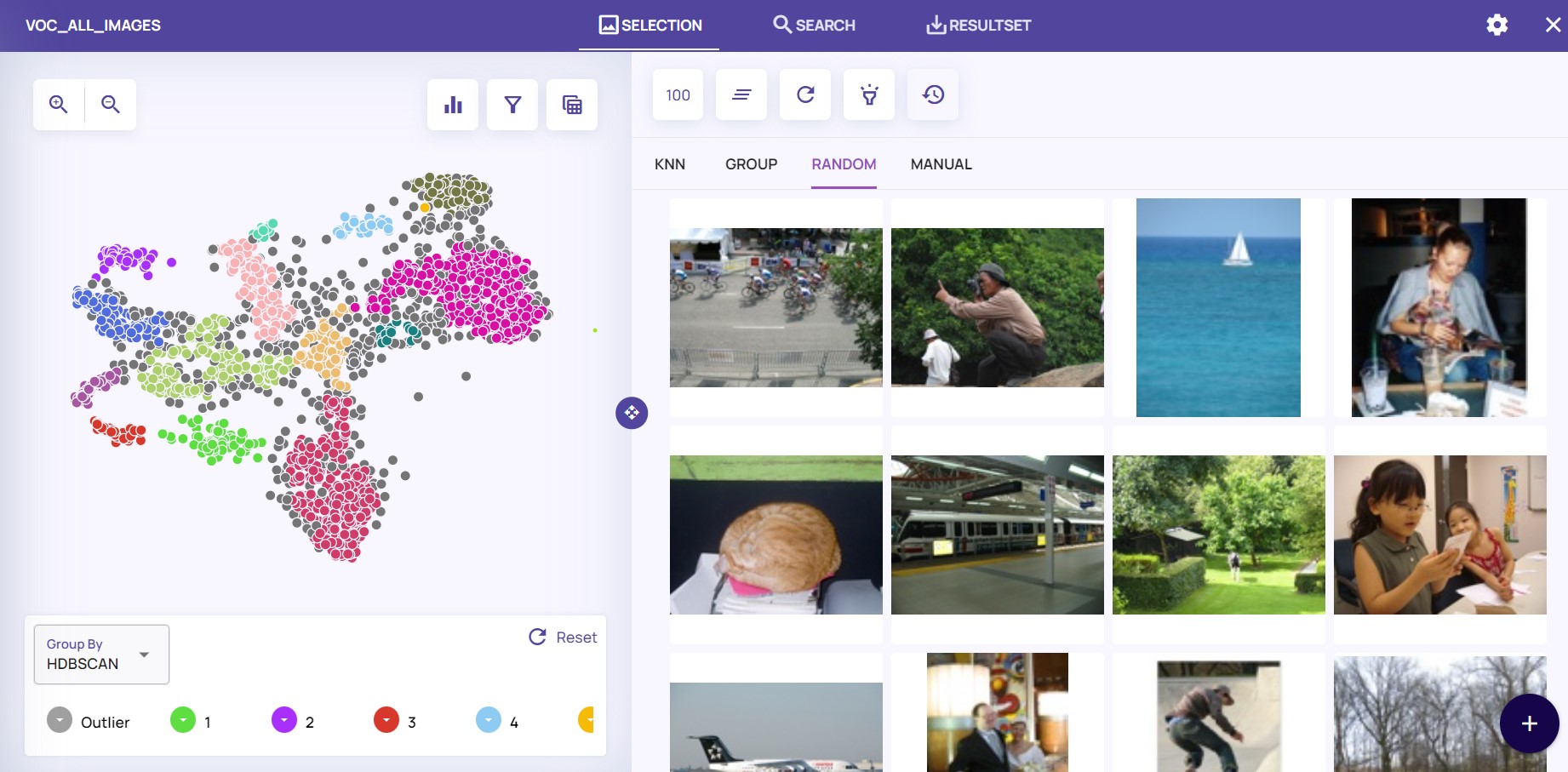
Data Explorer starts by representing each image with a feature vector, cluster them into groups and plotting the result on a 2D map.
The Pascal VOC 2012 data set is a widely used set of natural images. In the image below, we see how it was processed and visualized by Data Explorer:
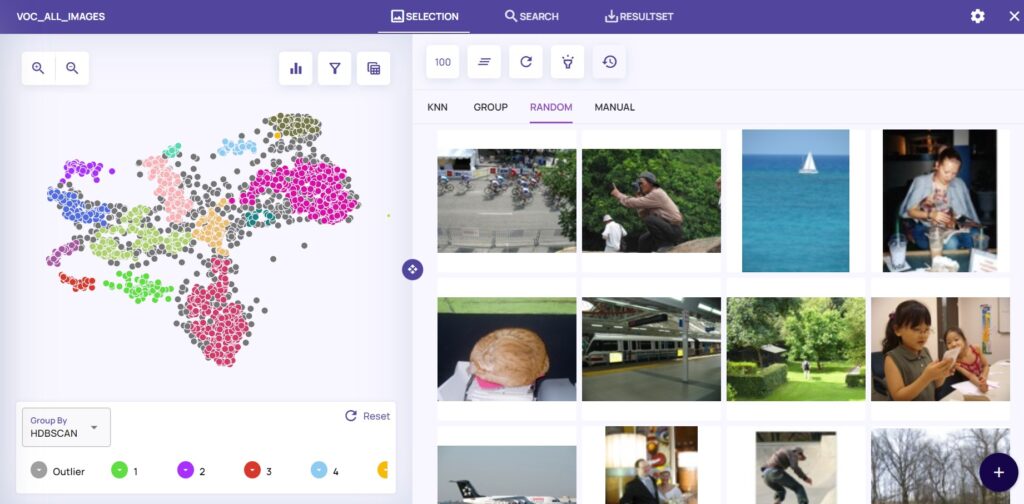
A 2D representation of 17K images from Pascal VOC dataset (left) and randomly selected images (right)
On the left, we see ~17K images automatically clustered into several groups; on the right, there are some examples, randomly chosen for review.
Data Explorer comes built in with a great featurizer, but it also supports custom options; in addition, there are several clustering algorithms so you could choose the most relevant for your data.
Summary
In this blog, we saw how a data set of images could be visualized, based on the raw images, no metadata involved. This is just a first step to review the quality of the data, clean it, and build a strong foundation to develop the next steps.
In the next article, we will see how the interactive UI allows us to explore the dataset, which insights to gain, and how to go one step closer to the desired clean dataset.



No Responses